Speech to Text: An Exploration of Evaluation Metrics for Telugu Language
Table Of Contents
- Abstract
- Introduction
- Methodology
- Results
- Data Normalization and Improvements
- Advanced Evaluation Metrics
- Findings
- Conclusion
- Future Research Directions
- References
1. Abstract
Accurate speech-to-text conversion plays a vital role in bridging communication gaps across languages. Subtitles are essential for comprehending videos in various languages, but ensuring their accuracy, especially for non-English or regional languages like Telugu, presents unique challenges.
This paper explores the evaluation metrics for speech-to-text transcription accuracy, particularly focusing on native languages. It examines how subtitles and transcription technologies, essential for translating regional languages like Telugu, ensure accuracy through various evaluation metrics.
Key metrics discussed include BLEU Score, Word Error Rate (WER), Character Error Rate (CER), and others, highlighting their effectiveness and limitations. The study aims to identify suitable metrics for improving transcription accuracy in native languages.
Keywords: Speech-to-Text, Evaluation Metrics, Telugu Language, Speech Recognition, Automatic Speech Recognition (ASR), BLEU Score, WER, CER.
2. Introduction
Technology bridges communication gaps in today’s globalized world by allowing individuals to understand content from various languages via intelligent systems. Native language forms the primary mode of communication in major parts of the world, and digital interaction in the native spoken language is paramount.
Imagine trying to communicate with someone who speaks a different language. While translators can help in person, media platforms rely on subtitles to bridge this gap.
Subtitles are essential for understanding videos in different languages, but creating accurate subtitles, especially for non-English or regional languages, involves complex processes. Speech-to-text conversion technology plays a crucial role in achieving this by transforming spoken words into written text.

Speech-to-text conversion technology plays a crucial role in transforming spoken words into written text, enabling applications like voice search, subtitling, and voice-enabled assistants.
Telugu, the fourth-most spoken native language in India and the 14th globally, with its influence rapidly spreading, including significant growth in countries like the United States, presents a compelling case for refining speech-to-text evaluation methods for native languages.
Accurate evaluation is essential to ensure the quality of subtitles, improve the accessibility of multimedia content for Telugu speakers, and enhance the overall user experience.
However, evaluating the accuracy of speech-to-text conversion for native languages poses challenges compared to English. Existing evaluation metrics, while well-established for English, might not be entirely suitable for languages like Telugu due to factors like:
Linguistic variations:
Native languages may have character or word variations that don’t affect the meaning but can lead to high error rates in metrics like WER and CER.
Sentence structure:
Sentence structures in native languages might differ from English, impacting the accuracy of metrics that focus on word order.
The transcription stage is at the heart of this challenge, wherein spoken language is transformed into written text. This pivotal phase not only determines the accuracy of subsequent translations but also significantly impacts the accessibility and inclusivity of content.
In light of these considerations, this research paper delves into the intricacies of the transcription stage, focusing on the specific nuances and challenges encountered when transcribing Telugu speech.
By analyzing the strengths and limitations of various metrics, we hope to contribute to the development of more reliable evaluation methods for native languages.
Problem Statement:
While there are benchmarked metrics available for English, this study aims to identify and evaluate suitable metrics of speech-to-text models for assessing the accuracy of transcribed data in native languages, ensuring reliable and meaningful translations.Speech to Text:
Speech-to-text conversion for existing media involves two primary tasks: transcription and translation. Transcription converts spoken language into written text, while translation converts this text into the target language. Accurate transcription is crucial for effective translation, especially for native languages.
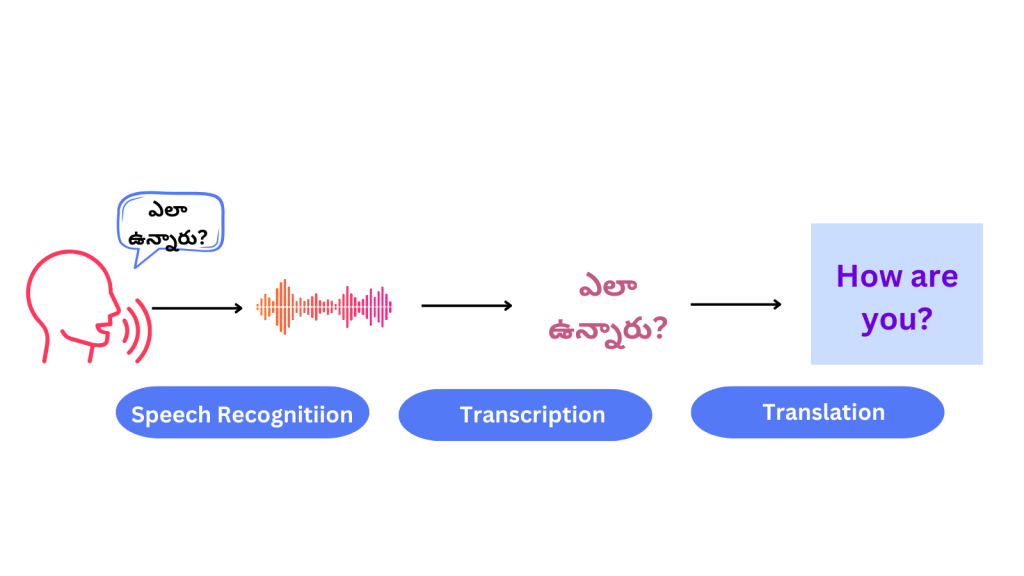
Real World Use Cases of Speech to Text Transcription:
Medical Transcription:
Doctors dictate patient notes which are converted using speech-to-text and stored in Electronic Health Records.
Call Centre Transcription:
Customer service interactions are transcribed and translated for documentation.
Meetings and Conferences:
Business talks and meetings are transcribed for documentation and minute preparation.
Legal Transcription:
Legal proceedings and court sessions are documented using transcription.
Education and E-Learning:
Lectures and educational videos are transcribed for accessibility and content searchability.
Broadcast Media:
Television, radio, movies, songs, live broadcasts, and recorded programs are transcribed into captions.
Content Creation:
Writers, bloggers, and journalists use transcription to note information from interviews and recordings.
Language Translation:
Transcription acts as a prerequisite for translating languages into a target language
3. Methodology
This study investigates the effectiveness of various evaluation metrics for Telugu speech-to-text conversion. We analyze two Telugu audio datasets, referred to as Audio 1 and Audio 2, for evaluation.
Datasets:
Audio Dataset 1 (Audio 1): This audio file is approximately 32 minutes long and has been segmented into 95 batches, each lasting 20 seconds. The file was manually transcribed (reference text) and transcribed using an automated system (machine text).
Audio Dataset 2 (Audio 2): This audio file is about 11 minutes and 30 seconds long, divided into 34 batches of 20 seconds each. Similar to Audio 1, this audio was also manually transcribed (reference text) and transcribed using an automated system (machine text).
Both the files were manually transcribed (reference text) and also transcribed using an automated system (machine text). Both of these were used for evaluation.
Evaluation Metrics:
We employed the following metrics to assess the accuracy of the speech-to-text transcriptions for Telugu
| Metric | Description | Range |
| BLEU Score | Measures the sequence of words in the generated text against reference text | 0 to 1 |
| Word Error Rate (WER) | Calculates word insertions, deletions, and substitutions, expressing errors as a ratio to the total words in the reference text. | 0 to 1 (WER = 0-> accurate) |
| Character Error Rate (CER) | Like WER but focused on characters, dividing the sum of errors by the total characters in the reference text. | 0 to 1 (CER = 0-> accurate) |
| Word Accuracy (WA) | Directly counts correctly transcribed words divided by the total words in the reference text. | 0 to 1 (WA = 1-> accurate) |
| Sentence Error Rate (SER) | Evaluates sentence-level errors, including insertions, deletions, and substitutions against the total sentences in the reference text. | 0 to 1 (SER = 0-> accurate) |
| Precision,Recall, and F1 Score | Measures the accuracy of transcriptions using true positives, false positives, and false negatives, with F1 Score balancing precision and recall. | 0 to 1 |
4. Results
We initially evaluated the two audio datasets using the aforementioned metrics. The results are presented in Table 1.
a) Initial Evaluation Results:
Table 1
| Metric | Audio 1 | Audio 2 |
| BLEU Score | 0.074 | 0.091 |
| WER | 0.677 | 0.538 |
| CER | 0.328 | 0.147 |
| Word Accuracy | 0.018 | 0.007 |
| SER | 0.656 | 0.507 |
| Precision | 0.634 | 0.586 |
| Recall | 0.575 | 0.622 |
| F1 Score | 0.603 | 0.603 |
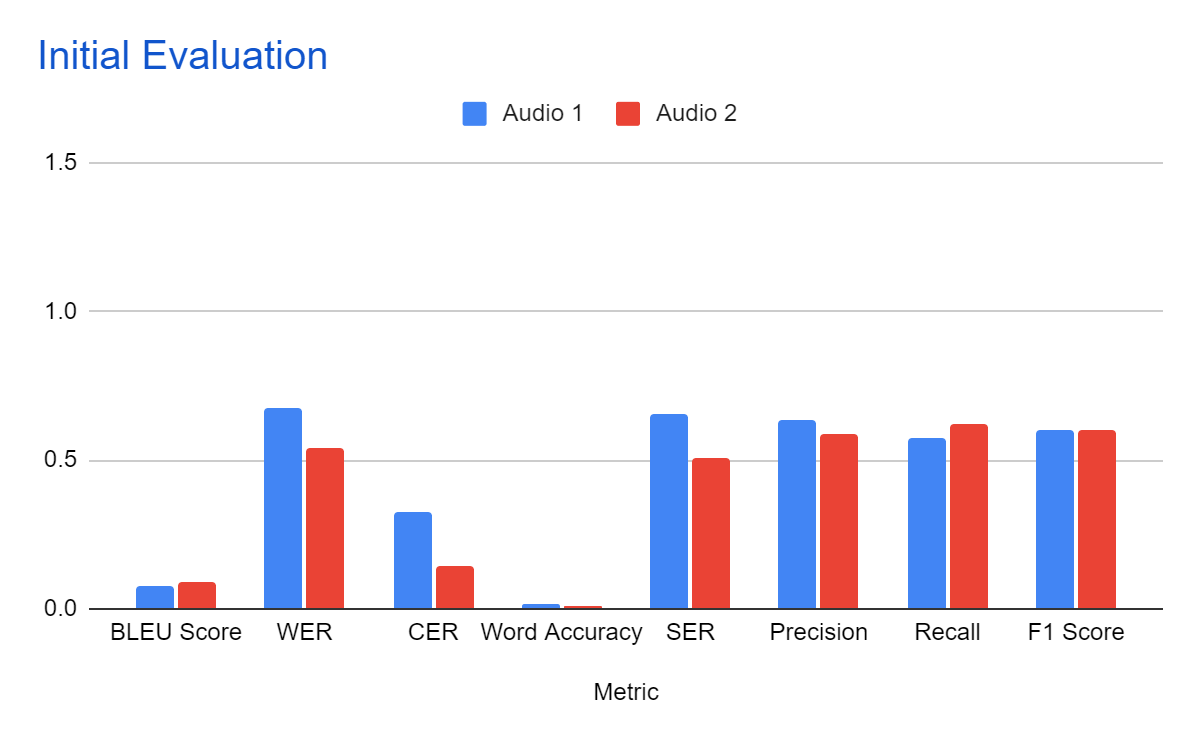
As observed in Table 1, WER and CER exhibited high error rates for both audio datasets. This suggests a significant discrepancy between the machine-generated text and the reference text.
5. Data Normalization and Improvements
To address the limitations of WER and CER for Telugu evaluation, we applied data normalization techniques and explored alternative evaluation methods.
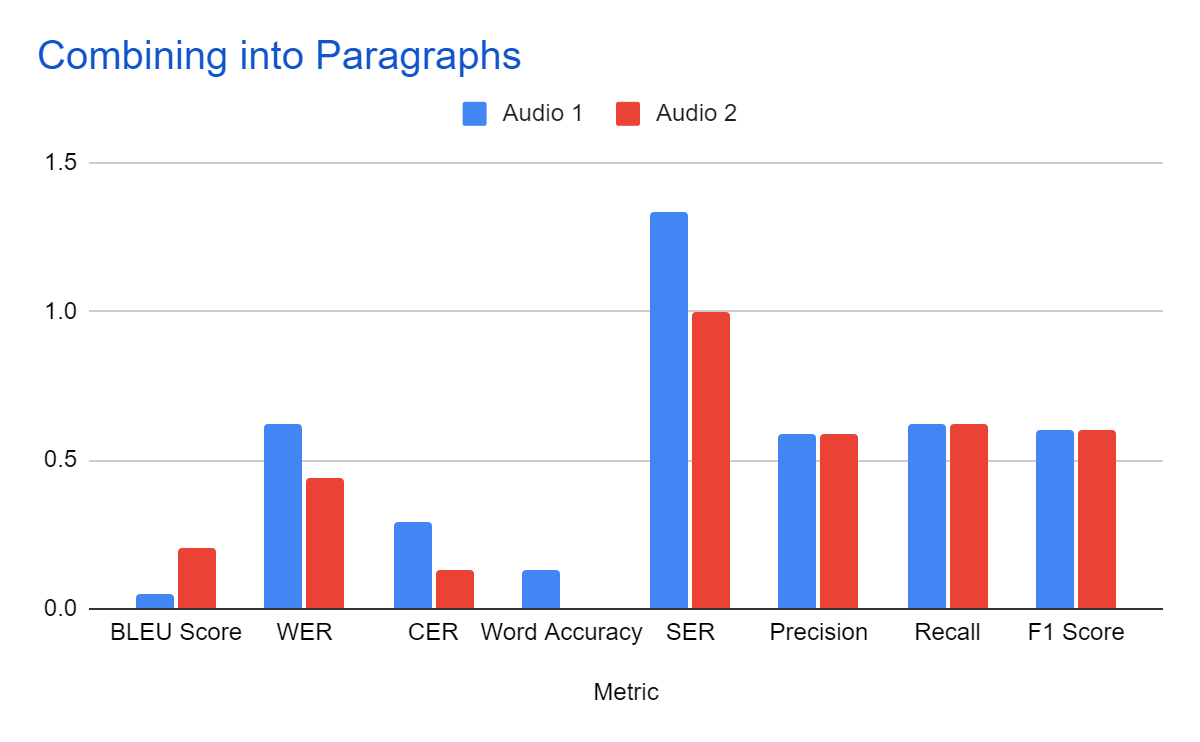
a) Modulating Data into Paragraphs:
The initial evaluation divided the audio data into 20-second batches. We re-evaluated the data after segmenting it into paragraphs. This changed the results, as shown in Table 2.
Table 2
| Metric | Audio 1 | Audio 2 |
| BLEU Score | 0.047 | 0.202 |
| WER | 0.624 | 0.443 |
| CER | 0.291 | 0.13 |
| Word Accuracy | 0.133 | 0.006 |
| SER | 1.333 | 1 |
| Precision | 0.586 | 0.586 |
| Recall | 0.622 | 0.622 |
| F1 Score | 0.603 | 0.603 |
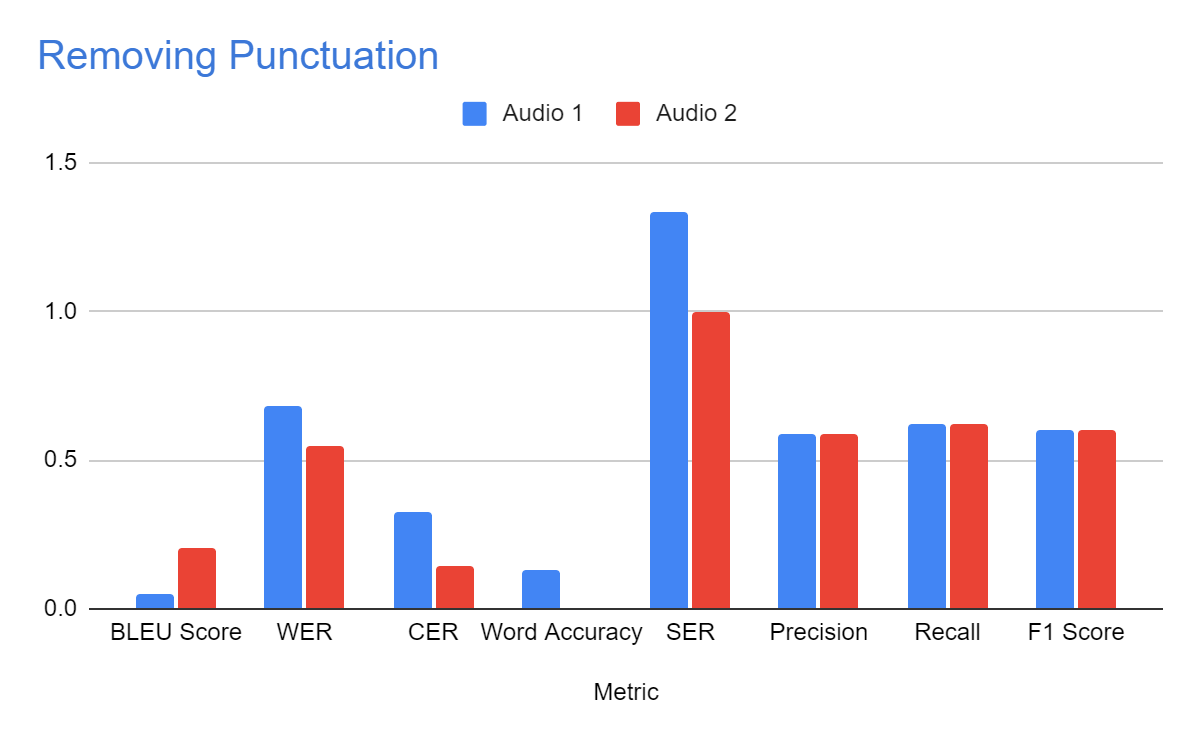
b) Normalization by Removing Punctuation Marks:
Removing punctuation marks from the system-generated text slightly adjusted the metrics as shown in Table 3
Table 3
| Metric | Audio 1 | Audio 2 |
| BLEU Score | 0.047 | 0.202 |
| WER | 0.685 | 0.547 |
| CER | 0.326 | 0.147 |
| Word Accuracy | 0.133 | 0.006 |
| SER | 1.333 | 1 |
| Precision | 0.586 | 0.586 |
| Recall | 0.622 | 0.622 |
| F1 Score | 0.603 | 0.603 |
The average percentage of all metrics showed a slight improvement:
Table 4
| Data Set | Average Percentage |
| Audio 1 | 57.62% |
| Audio 2 | 49.68% |
c) Adjustments for Native Language Specifics:
Telugu-specific nuances such as minor character differences that do not change meaning affect metrics like WER and CER. For instance, the words “పార్టీ” and “పార్టి” both mean “party” despite a character difference.
Therefore, it is suggested to skip WER and CER and focus on Word Accuracy for a more reliable measure of transcription performance.
Table 5
| Metric | Audio 1 | Audio 2 |
| Word Accuracy | 0.452 | 0.469 |
d) Sentence Error Rate (SER) Adjustments:
Initial attempts showed a consistent SER of 1.0. After refining methods and adjusting the text structure, SER values improved significantly.
Table 6
| Metric | Audio 1 (Adjusted) | Audio 2 (Adjusted) |
| SER | 0.652 | 0.507 |
| SER (After removing sentences) | 0.821 | 0.597 |
| SER (After adding false positives) | 0.51 | 0.522 |
e) Improvements with Tokenization:
Tokenization, dividing sentences into words or subwords, significantly improved BLEU scores.
Table 7
| Metric | Audio 1 (Tokenized) | Audio 2 (Tokenized) |
| BLEU Score | 0.31 | 0.22 |
These findings suggest that tokenization is a valuable technique for adapting the BLEU Score to better evaluate Telugu speech-to-text accuracy.
6. Advanced Evaluation Metrics
We explored some advanced evaluation metrics to assess their suitability for Telugu speech-to-text evaluation:
a) Position Independent Word Error Rate (PIWER):
Similar to WER, PIWER calculates word-level errors but ignores the order of words in the sentence. While PIWER can be helpful in certain scenarios, it might not be ideal for Telugu evaluation as word order can sometimes impact meaning.
b) Position Independent Character Error Rate (PICER):
Similar to CER, PICER calculates character-level errors while disregarding character order. Like PIWER, PICER might not be suitable for Telugu due to the importance of character order in conveying meaning.
c) Segmentation Error Rate:
This metric evaluates errors across segmentation boundaries (e.g., sentence breaks). While segmentation errors can be crucial for some applications, they might not be the primary focus for evaluating the core accuracy of speech-to-text conversion in Telugu.
d) ROUGH Score:
This metric measures the similarity between words or sequences, making it more suitable for evaluating translation quality than speech-to-text conversion accuracy.
Based on this analysis, we determined that Word Accuracy and BLEU Score (with tokenization) emerged as the most effective metrics for evaluating Telugu speech-to-text conversion in our study.
7. Findings
Limitations of WER and CER: WER and CER might not be well-suited for Telugu evaluation due to their sensitivity to minor, non-meaning-altering character variations.
Importance of Word Accuracy: Word Accuracy provides a more reliable measure of correctly transcribed words for Telugu speech-to-text conversion.
Effectiveness of BLEU Score with Tokenization: BLEU Score, when combined with tokenization to account for Telugu morphological characteristics, can be a valuable metric for Telugu evaluation.
Limited Usefulness of Advanced Metrics: Advanced metrics like PIWER, PICER, and Segmentation Error Rate might not be ideal for core speech-to-text accuracy evaluation in Telugu due to their focus on aspects like word order or segmentation boundaries.
8. Conclusion
This study explored the challenges of evaluating speech-to-text accuracy in Telugu and the limitations of traditional metrics like WER and CER.
Our analysis of two Telugu audio datasets revealed their sensitivity to minor character variations that don’t impact meaning.
We investigated alternative metrics and data normalization techniques, and based on the findings, we conclude that:
- Word Accuracy emerged as a reliable metric for measuring correctly transcribed words in Telugu speech-to-text conversion.
- BLEU Score, when combined with tokenization to account for Telugu morphology, proved to be a valuable tool for evaluating Telugu speech-to-text accuracy.
The final average percentages of these metrics were
Table 8
| Data Set | Average percentage |
| Audio 1 | 40% |
| Audio 2 | 35.40% |
These findings provide valuable insights for researchers and developers working on speech-to-text technology for Telugu and other native languages.
9. Future Research Directions
Future work should explore further refinements to these evaluation methods, considering the specific linguistic features of Telugu and other native languages.
Additionally, developing custom metrics that can better handle language-specific nuances would enhance the accuracy and reliability of transcription evaluations in regional languages.
10. References
1. https://www.assemblyai.com/blog/how-to-evaluate-speech-recognition-models/
2. https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
4. https://www.dataknobs.com/blog/speech-analytics/
5. Papineni, Kishore & Roukos, Salim & Ward, Todd & Zhu, Wei Jing. (2002). BLEU: a Method for Automatic Evaluation of Machine Translation. 10.3115/1073083.1073135.
6. https://github.com/ChiZhangRIT/BLEU_Mandarin